
AI’s got its gloves on, training hard for rounds in residency review and crushing board questions.
The battle of brains is on, and OpenAI’s (California, USA) o1 Pro has landed a decisive uppercut. In a head-to-head match of ophthalmology board-style questions, this reasoning model emerged the undisputed champion, correctly answering 83.4% of questions in a recent study published in Scientific Reports.1
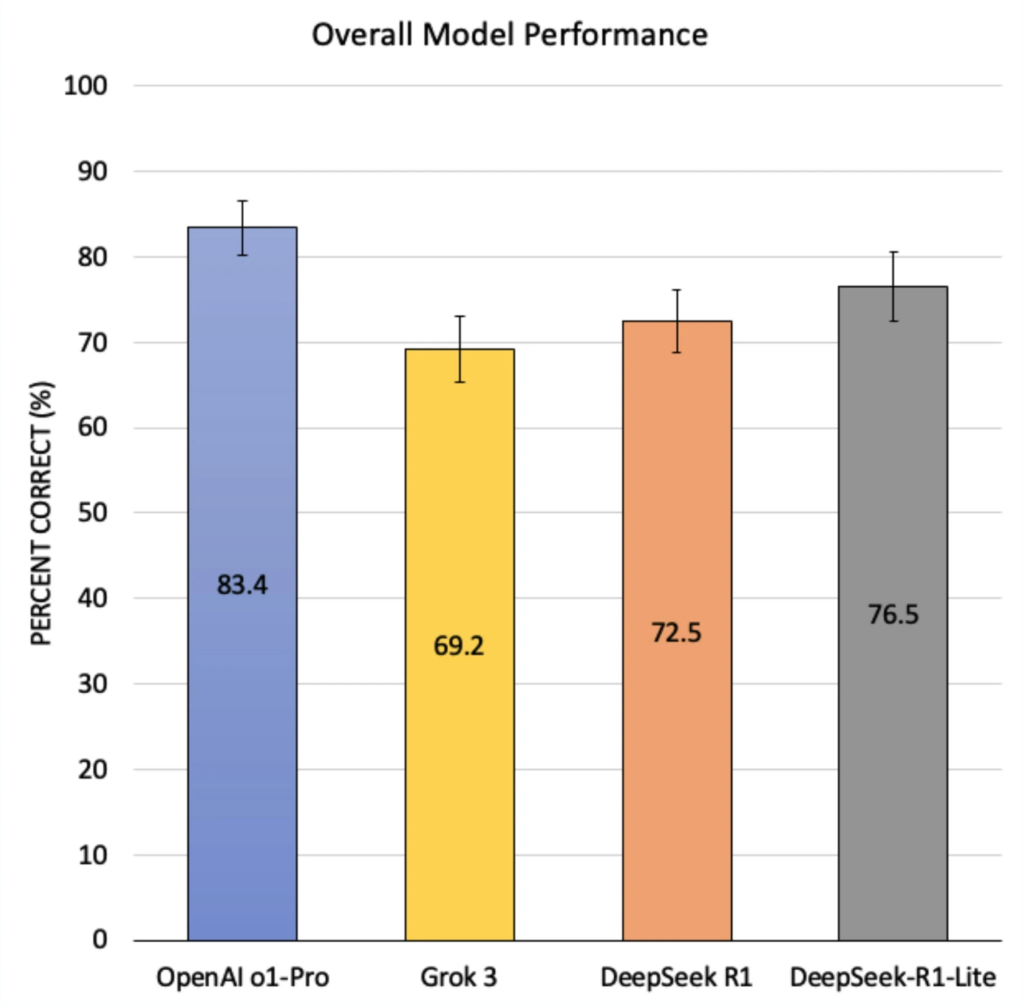
Facing off against rivals DeepSeek-R1-Lite (76.5%; High-Flyer, Hangzhou, China), DeepSeek R1 (72.5%) and Grok 3 (69.2%; xAI, California, USA), o1 Pro outperformed across nearly every subspecialty and complexity tier, showing promise for both clinical decision-making and medical education.1
READ MORE: New AI Model Transforms Optic Disc Photos into Glaucoma Risk Predictors
Round-by-round performance
In a comprehensive evaluation led by Ryan Shean and colleagues, 493 questions from StatPearls and EyeQuiz formed the arena. Across nine ophthalmology subspecialties, o1 Pro topped the charts in eight. Its performance in the heavyweight category (Cornea, External Disease and Anterior Segment) was particularly commanding, with 80.3% accuracy. That compares to 74.6% for DeepSeek-R1-Lite, 70.5% for Grok 3 and 66.4% for DeepSeek R1.1
The lone round it didn’t win? Uveitis, where o1 Pro came in second. But with just 11 questions in the category, even the judges (researchers) admitted the sample size was too small for a proper scorecard.1
Thinking on its feet
When it came to question difficulty, DeepSeek-R1-Lite eked out a win in first-order (recognition and recall) questions with 86.5%, nudging past o1 Pro’s 81.1%. But o1 Pro took the title in higher-order thinking:
- Third-order questions (application/problem-solving): 86.3%
- Second-order questions (comprehension/interpretation): 81.6%1
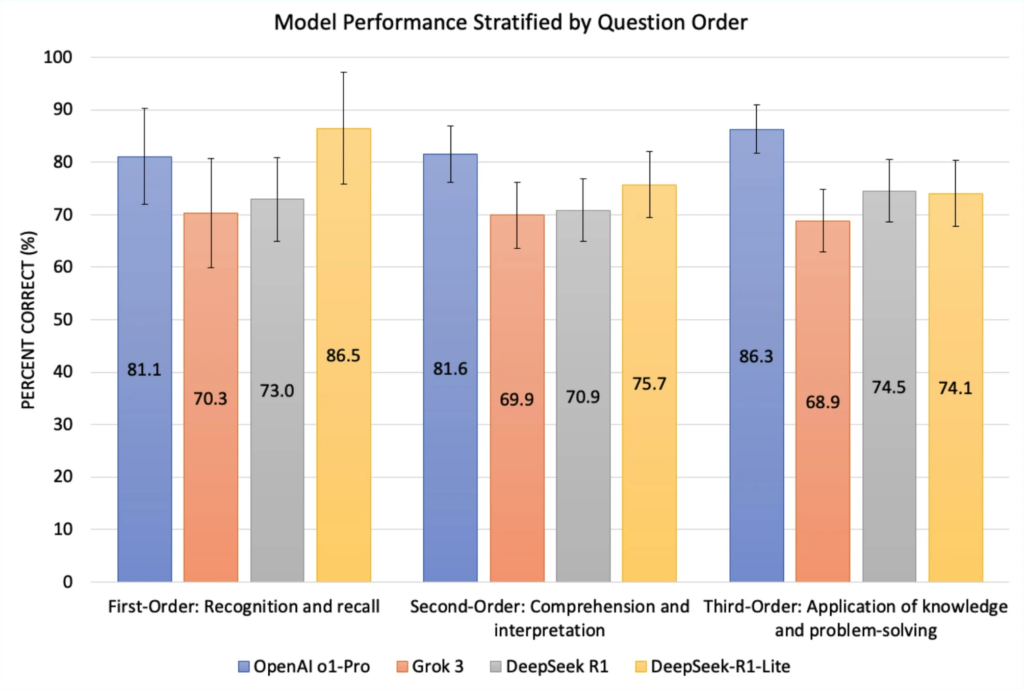
In short, when the questions get tough, o1 Pro keeps its gloves up.
Handling image-based questions
Image-based questions proved a challenge across the board, but o1 Pro held its form, showing only a 1.4% drop in performance compared to text-only questions. Grok 3, on the other hand, stumbled, with an 11.6% gap.1
A surprise contender
In an unexpected twist, DeepSeek-R1-Lite outperformed its heavyweight teammate, DeepSeek R1, despite having just 15 billion parameters compared to R1’s 671 billion. This featherweight’s efficient use of resources suggests that strong AI performance doesn’t always require massive compute power.1
“DeepSeek-R1-Lite’s balance of strong performance, low memory requirements and affordability suggests that it may be possible to achieve LLM-based educational support without relying exclusively on the most expensive, high-resource model,” the researchers noted.1
READ MORE: Emerging Waves in Digital Eye Health: From AI Models to Smartphone Clinics
What it means for ECPs
The models’ strong performance on board-style questions—outpacing prior studies that reported LLM accuracy between 46.7% and 71%—suggests exciting potential for residency training, board prep and clinical support.1
Still, this fight isn’t over. The researchers caution that real-world clinical data and outcomes-based validation are essential before these models can step fully into clinical rings.1
But if this study is any indication, AI’s footwork in ophthalmology is getting sharper. And while it might not be time to throw in the towel on traditional methods, you might just want to start training with a new kind of sparring partner.
READ MORE: EyeCLIP and the State of Multimodal AI in Ophthalmology
Reference
- Shean R, Shah T, Pandiarajan A, et al. A comparative analysis of DeepSeek R1, DeepSeek-R1-Lite, OpenAi o1 Pro, and Grok 3 performance on ophthalmology board-style questions. Scientific Reports. 2025;15:23101.